BrainHack TIL-AI 2026
 IRS ML @ TIL-26
IRS ML @ TIL-26
BrainHack TIL-AI is one of the flagship competitions that IRS participates in. In this competition, we train models across a diverse range of tasks (CV, ASR, NLP) and compete against other teams during the semi-finals and finals with the AE task.
Initially, my team, consisting of Cao Xizhen, Chen Yuzhe, Rafael Chong and Gao Zhongreng registered for TIL thinking that we would be placed in the Advanced track. After all, two of our teams (Yuzhe’s and mine) managed to attain a semifinalist position in last year’s edition of TIL.
Possibly due to sheer luck, we were placed in the Novice category. But we made the mistake of underestimating Novice at the start- although the tasks are less complex than the ones in advance, the competition was comparably sweaty. With competitors from JC, University, Polytechnic teams and even NSFs, we had to battle against the odds to beat teams with considerably more experience than us.
While we placed 2nd in qualifiers, we suffered defeat in the finals, ultimately achieving 5th place out of 68 teams overall. This blog post details my experience, including the technical challenges faced, my approach to the tasks as well as some reflection on the overall journey and my thoughts on how this competition can be removed.
My Contributions
Automatic Speech Recognition (ASR)
Your automatic speech recognition challenge is to transcribe a noisy recording of speech. Given an audio file, your model is expected to produce a text transcript of what was spoken.
In each audio file, there is only one speaker. Note that many of the words used within each audio file are not necessarily normal dictionary words. The generated audio is all set in the fictional world of the NLP RAG corpus, which means it will include various slang terms and jargon relevant to that world.
When listening to the audio files, I found that most of the dataset consisted of noised Indian-accented audio. I experimented with both OpenAI Whisper and NVIDIA Parakeet models for this task.
A summary of our base model results are shown below:
| Model | Score | Speed |
|---|---|---|
| Systran/faster-whisper-large-v3 (base) | 0.968 | 0.483 |
| nvidia/parakeet-tdt-1.1b (base) | 0.987 | 0.863 |
| nvidia/parakeet-tdt-ctc-1.1b | 0.988 | 0.877 |
| nvidia/parakeet-ctc-0.6b | 0.983 | 0.900 |
| nvidia/parakeet-tdt-0.6b-v2 | 0.956 | 0.934 |
Note that the the first 4 of these metrics were evaluated before a bugfix was applied, making the scores artificially inflated. However, it was clear that the correct direction was to use a parakeet model instead of Whisper as it is significantly faster.
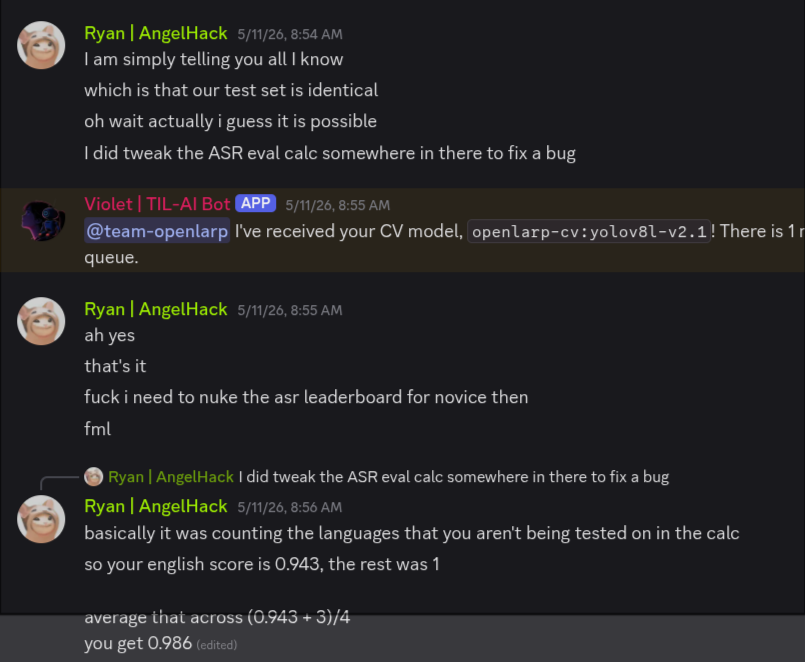 Said bug
Said bug
An attempt was made to finetune these parakeet variants: 0.6b-tdt-v2, 0.6b-ctc, 1.1b-tdt. While 0.6b-ctc was the fastest model, it showed poor generalisation from the finetuning, while 0.6b-tdt-v2 performed the best and was ultimately chosen as the model for finals due to its high score as well as high speed relative to the other models.
| Model | Score | Speed |
|---|---|---|
| nvidia/parakeet-tdt-0.6b-v2 (20 - early stop at 18) | 0.992 | 0.942 |
| nvidia/parakeet-tdt-0.6b-v2 (20 - early stop at 7) | 0.979 | 0.916 |
| nvidia/parakeet-tdt-1.1b (14 epochs) | 0.983 | 0.916 |
| nvidia/parakeet-tdt-0.6b-v2 (30 - early stop at 24) | 0.986 | 0.940 |
| nvidia/parakeet-rnnt-0.6b (7 epochs) | 0.952 | 0.917 |
In addition, the following speed optimisations were made: (by Claude)
ASR Manager
Shared memory for temp files. Intermediate WAV files are written to /dev/shm rather than a regular disk path.
Parallel file writes. A module-level ThreadPoolExecutor with 4 workers is created once at import time and reused across all calls. Within batch_asr, each audio blob is written to its temp file on a separate thread, so the writes happen concurrently rather than sequentially. The futures are collected and resolved before transcription begins.
True batching. Rather than transcribing one file at a time, all audio in a single request is passed to model.transcribe together as a list, with batch_size set to the full count. This lets the GPU process the whole group in one forward pass instead of N serial passes.
num_workers=0. The NeMo DataLoader is told not to spin up subprocess workers. Subprocess workers carry fork/spawn overhead and inter-process communication cost; for short-lived inference requests where the bottleneck is the GPU, zero workers is often faster than the default.
verbose=False. Suppresses NeMo’s per-batch progress output, removing the overhead of writing to stdout on every transcription call.
CUDA placement. The model is moved to GPU at load time if one is available, so all inference runs on the accelerator rather than CPU.
Warm-up pass. A dummy silence batch is transcribed at startup. This forces CUDA kernels, JIT compilations, and any lazy NeMo initialisation to complete before the first real request arrives, so the first live request doesn’t pay that latency penalty.
Server
orjson for JSON parsing. The request body is parsed with orjson instead of the standard library json. orjson is implemented in Rust and is consistently faster at both decode and encode, which matters when payloads contain large base64 strings.
Fast base64 decoding. pybase64 is preferred over binascii.a2b_base64 when available. pybase64 wraps the native libbase64 SIMD implementation and decodes significantly faster than the Python standard library, which is relevant for large audio blobs.
Batch endpoint. The /asr route accepts an instances array rather than a single audio blob per request. This means multiple audio chunks can be sent in one HTTP round-trip and processed as a single GPU batch, avoiding the per-request HTTP and scheduling overhead that would accumulate if each chunk were a separate call.
Raw Response return. The handler returns a Response object with pre-serialised bytes rather than returning a dict and letting FastAPI serialise it. This skips FastAPI’s response model validation and jsonable_encoder pass, which adds latency with larger payloads.
Computer Vision (CV)
 Sample image in CV dataset
Sample image in CV dataset
Your CV challenge is to detect and classify objects in an image. Given an image, your model is expected to produce the bounding box and predicted category of every occurrence of an object belonging to a category in the target list. Each scene may contain zero or more targets.
- Model: RF-DETR-Large, DINOv2 backbone,
patch_size=16, inferenceresolution=1280. Second model for ensembling: YOLO (yolo11l). - Classes: 18 (aircraft / vehicle / ship types).
- Metric (leaderboard-matched, “evaluator mode”): COCO mAP@[.5:.95] where kept detections are filtered at an operating threshold and all scores are flattened to 1.0 (the submission carries no confidence field). This single fact invalidates a whole family of techniques — see §5.
- Hard-val: 1000 images, 3721 GT boxes. Used as the leaderboard proxy
The resolution was selected to be 1280px after many rounds of trial and error. More details can be found in our model tracking sheet here. Do note it’s quite messy and it doesn’t account for some of the models towards the end (as I was in a rush).
Dataset analysis
The initial dataset was first augmented to produce a larger dataset (til26_aug_v3) with more copies of small objects, and of course increased noise, which appeared to be the main bottleneck in the object detection task.
| train | hard-val | |
|---|---|---|
| images / boxes | 30000 / 107487 | 1000 / 3721 |
| boxes per image | 3.6 | 3.7 |
| size: small (<32²) | 6.5% | 2.5% (94 boxes) |
| size: medium (32²–96²) | 70.9% | 52.8% |
| size: large (>96²) | 22.6% | 44.7% |
| degenerate / out-of-bounds boxes | 0 / 0 | 0 / 0 |
| image resolution | 1280×720 (all) | 1280×720 (all) |
Some stats from Claude
-
Small objects are 2.5% of the eval (94 boxes).
mAP_small=0.41is noisy and near-irrelevant to the headline; 97.5% of the score is medium/large objects. This retroactively explains why every small-object lever failed. -
Source imagery is 720p; worst classes are ~45 px across. IoU@0.95 on a 45-px object is near-impossible — a real source-resolution ceiling, not a model defect.
-
Labels are geometrically clean (0 degenerate, 0 OOB), and the box-bias measurement (§5) shows predictions are well-sized — so the high-IoU scatter is inherent regression noise, not annotation geometry.
-
300 object queries for 3.6 objects/image → queries are wildly over-provisioned and are not a bottleneck.
-
Minor train↔val size mismatch (train skews smaller than val) from the copy-paste augmentation.
Afterwards, a finals set was created with added noise to protect our CV model from noise. Augv3 was trained on photometric noise only but the adversarial attacks used in finals would be a problem. A new finals augmentation profile was created to train the models against real attacks, such as decoys and region destruction (based on my teammate horse3903’s NOISE model). This proved to be effective based on our validation set.
| model | clean mAP | noised mAP |
|---|---|---|
| augv3 | 0.966 | 0.592 |
| finals | 0.970 | 0.809 |
Up until the day of semi-finals, I thought that CV was settled and my best RFDETR model (score 0.775) was good enough for finals. However, on the day of semi-finals, we discovered that the CV model underperformed relative to other teams (likely due to the noise applied), so I made a last ditch attempt to finetune my YOLO model further and used it for the ensemble in the end. My final discord evaluation attained a score of 0.781 and a speed of 0.940, beating all previous models.
Autonomous Exploration (AE)
 AE at TIL Finals - credits: taxevashawn on Discord
AE at TIL Finals - credits: taxevashawn on Discord
My work on AE picked up from the algorithm that my teammates burner972021 and horse3903 worked on during qualifiers. After qualifiers, we concluded that an alogorithm-only approach wasn’t going to suffice for finals so we opted to switch to training RL.
The algorithm made use of a map aware planner using BFS navigation, greedy path-value collection and base-bombing economy. Using Claude, I improved the qualifiers model marginally by adding a defense wrapper to reactively defend the base late game, which attained a score of 0.824 against the benbots.
Afterward, I worked on a CNN-actor critic PPO agent for our RL approach, in contrast to the MLP model that burner972021 was working on. The first step of the training process was imitation learning via behaviour cloning (BC), based on the best algorithm developed earlier.
At the same time, I did research into other RL approaches for bomberman-style games, and came across Pommerman, a multi-agent environment based on the classic console Bomberman. Through looking at some papers, ideas such as used DQfD (Deep Q-learning from Demonstrations) and MCTS (Monte-Carlo Tree Search) surfaced, but they failed to provide any meaningful results and I stuck with my CNN-actor critic PPO agent.
In the end, we chose burner972021’s AE model which used an oracle choosing different RL checkpoints based on their performance for each spawn slot.
Thoughts
Overall, it was a really fun experience participating in TIL again. But here’s some feedback on this year’s TIL:
-
I felt that the CV, NLP and ASR were not given high enough weighting in the finals. For almost all of the finals/semifinals games, the multiplier (given by these tasks) for most teams were quite similar, ranging between 0.88-0.92. I felt that this placed unnecessary empahsis on the AE tasks when the other tasks also required a substantial amount of effort, so when everyone got a similar multiplier it felt unfair. Perhaps this could be mitigated by making the challenges harder so it’s easier to differentiate between the teams.
-
The finals and semi-finals games were only run once, which meant that it relied heavily on RNG, as each team was placed at a different spawn point. Furthermore, the evaluation during qualifiers/before semis was played against BenBots, which understandably failed to be a realistic gauge of how our agents would do against each other in the finals. Overall the performance of models in the live games were quite heavily dependent on factors outisde of our control. Perhaps running the live games over more rounds would even out this variance so teams that can consistently perform well win instead of teams that got lucky for whatever reason.
-
This is more of a complaint (?) about the overall structure of the competition itself, but it benefits p2w players more. Although this can be said about everything (since you can just buy Claude Max or anything to slop nowadays), my main issue was that compute isn’t a cheaply accessible resource and teams (including ours) are disproportionately benefitted because we can train larger models in a shorter time and continuously try out different approaches without causing bottlenecks on GCP or other free platforms. Even so, I still really enjoyed playing TIL - it’s not something you can just vibecode in a day (given the number of CTFs that are just being vibed). There is still continuous testing, evaluating and innovating required to do well for this competition. I think this aspect makes our AI competition resilient against full AI slop in the age of tools like Claude Max. (I wonder how Fable would would perform on these tasks - it was just released on the day of TIL semis). Seeing that CTFs are just being slopped nowadays, I hope that TIL doesn’t become the same and can still offer learning value to players.
Looking forward to participating again in subsequent years!