What exactly is cross-entropy loss?
In this post, I’ll discuss what I’ve learnt about the intuition behind cross-entropy loss. This was heavily inspired by Chapter 7 of Stanford’s Speech and Language Processing textbook, and Adian Liusie’s video on the topic.
What is cross-entropy loss?
From Wikipedia:
In information theory, the cross-entropy between two probability distributions p and q , over the same underlying set of events, measures the average number of bits needed to identify an event drawn from the set when the coding scheme used for the set is optimized for an estimated probability distribution q , rather than the true distribution p .
Essentially, cross-entropy loss is used to measure the difference between the model’s predicted probabilities and the actual probabilities. The higher the cross-entropy loss, the greater the difference between your model’s predictions and the actual probabilities. Thus, cross-entropy loss is known as a loss function which we minimise in machine learning through backpropagation in order to build models with higher accuracies.
The basis of cross-entropy loss
Cross-entropy loss is based on Kullback-Leibler (KL) divergence, which is a measure from information theory that measures the difference between probability distributions.
Let’s say we had 2 coins,
For example, if our sequence was HTHHTTH, we get and for Coin 1 and 2 respectively.
Simplifying, we get and , where is the number of heads and is the number of tails.
Let’s calculate the ratios of the likelihood of observations of each coin:
To normalize for the number of samples, let’s take that to the power of 1/N, so that when we log we get:
Expanding, we get:
Which simplifies to:
If the observations are generated by coin 1, as the observations grow to infinity, the expected proportion of heads will tend to and the proportion of tails will tend to . By taking the limit, becomes and becomes .
Thus we can further simplify to
Which then becomes
And that’s the KL Divergence!
Deriving cross-entropy loss
In a machine learning classification task, we have a list of possible classes and the respective probabilities, giving a probability distribution.
Let the input image be and the predicted class distribution is , where is the model’s parameters. The true class distribution is .
Now we want to apply the KL Divergence (explained above):
Notice that the first term doesn’t depend on , the model’s parameters. So if we want to minimise this with respect to the model’s parameters, it’s the same as only minimising the second term
And that’s the formula for cross-entropy loss!
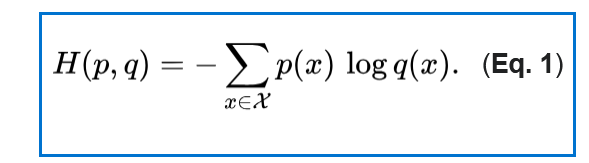 Cross-Entropy Loss Formula
Cross-Entropy Loss Formula
Conclusion
Cross-entropy loss is a very popular loss function used in multi-class classification problems. It’s a highly intuitive way of finding the difference between probability distributions. Hope that this article was useful!